오늘은 데이터 전처리, 특징 엔지니어링, 선형회귀
다중 선형회귀, 모델평가, 로지스틱 회귀 개념과 활용, 모델 성능 평가와 다중 분류에 대해서 배웠다.
아무래도 앞서 통계에서 다뤘던 개념들이 있어 빠르게 나갔던것 같다.
학습목표
- 데이터 전처리와 특징 엔지니어링, 선형회귀 개념과 원리
- 다중 선형회귀, 모델평가, 로지스틱 회귀 개념과 활용, 모델 성능 평가와 다중 분류
1. 데이터 전처리(Data Preprocessing)
데이터 전처리는 원시 데이터를 머신러닝 모델에 적합한 형태로 변환하는 과정입니다. 데이터에는 결측값, 이상치, 중복 데이터 등이 포함될 수 있으며, 이를 처리해야 모델이 효과적으로 학습할 수 있습니다.
1) 데이터 정리 및 탐색
데이터를 정리하고 구조를 이해하는 단계입니다.
- 데이터 로드: pandas, NumPy 등을 활용하여 데이터를 불러옴
- 기초 통계 확인: df.describe(), df.info() 등을 이용하여 데이터 타입과 분포 확인
- 데이터 시각화: matplotlib, seaborn을 사용해 변수 간 관계 파악
2) 결측값(Missing Values) 처리
결측값은 데이터셋에 값이 없는 부분을 의미하며, 적절히 처리하지 않으면 모델의 성능이 저하될 수 있습니다.
(1) 결측값 확인
import pandas as pd
df.isnull().sum() # 결측값 개수 확인
(2) 결측값 처리 방법
- 삭제(Dropping): 결측값이 적은 경우 해당 행 또는 열 제거
- df.dropna(inplace=True)
- 대체(Imputation): 평균, 중앙값, 최빈값 또는 예측값으로 결측값을 채움
- df.fillna(df.mean(), inplace=True) # 평균값으로 대체
- df.fillna(df.median(), inplace=True) # 중앙값으로 대체
- df.fillna(df.mode().iloc[0], inplace=True) # 최빈값으로 대체
- 예측 모델 활용: 머신러닝 모델을 이용해 결측값을 예측하고 보완
3) 이상치(Outliers) 처리
이상치는 데이터 분포에서 벗어난 극단적인 값으로, 모델 성능을 저하시킬 수 있습니다.
(1) 이상치 탐색
- 박스플롯(Box Plot) 활용
import seaborn as sns
sns.boxplot(x=df['feature_column'])- Z-Score 활용
from scipy import stats
z_scores = stats.zscore(df['feature_column'])
df = df[(z_scores < 3)] # Z-score가 3 이상이면 이상치로 간주하여 제거
- IQR(Interquartile Range, 사분위 범위) 활용
Q1 = df['feature_column'].quantile(0.25)
Q3 = df['feature_column'].quantile(0.75)
IQR = Q3 - Q1
df = df[(df['feature_column'] >= Q1 - 1.5 * IQR) & (df['feature_column'] <= Q3 + 1.5 * IQR)](2) 이상치 처리 방법
- 제거(Removal): 이상치를 제거하는 방식
- 대체(Replacement): 중앙값 또는 평균값으로 변경
- 변환(Transformation): 로그 변환, 제곱근 변환 등 사용
4) 데이터 정규화 및 스케일링
특징 값(Feature Value)의 크기가 다를 경우 모델 성능에 영향을 미칠 수 있으므로 스케일링을 수행해야 합니다.
(1) 정규화(Normalization)
- 모든 값을 0~1 범위로 변환
- MinMaxScaler 사용
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df[['feature1', 'feature2']] = scaler.fit_transform(df[['feature1', 'feature2']])(2) 표준화(Standardization)
- 평균이 0, 표준편차가 1이 되도록 변환
- StandardScaler 사용
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df[['feature1', 'feature2']] = scaler.fit_transform(df[['feature1', 'feature2']])
2. 특징 엔지니어링(Feature Engineering)
특징 엔지니어링은 모델이 학습할 수 있도록 적절한 특징을 생성하거나 변환하는 과정입니다.
1) 새로운 특징 생성
새로운 변수(Feature)를 추가하여 모델의 성능을 향상할 수 있습니다.
(1) 기존 변수 조합
- 예) 키와 몸무게를 이용해 BMI(체질량지수) 생성
df['BMI'] = df['Weight'] / (df['Height']**2)(2) 날짜 정보 변환
- 날짜 데이터를 요일, 월, 연도 등으로 변환
df['date'] = pd.to_datetime(df['date'])
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
df['weekday'] = df['date'].dt.weekday # 0: 월요일, 6: 일요일
(3) 텍스트 데이터 변환
- 단어 빈도수, TF-IDF 벡터화 등을 활용해 숫자로 변환
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(df['text_column'])
2) 특징 선택(Feature Selection)
모든 변수를 사용하는 것이 아니라, 모델 성능을 높이는 중요한 변수만 선택하는 과정입니다.
(1) 상관계수(Correlation) 활용
- 높은 상관관계를 가진 변수만 선택
import seaborn as sns
import matplotlib.pyplot as plt
corr_matrix = df.corr()
sns.heatmap(corr_matrix, annot=True, cmap="coolwarm")
(2) 중요도 기반 선택
- 랜덤 포레스트 모델을 사용해 변수 중요도를 확인
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train)
feature_importances = pd.Series(model.feature_importances_, index=X_train.columns)
feature_importances.sort_values(ascending=False).plot(kind='bar')
3) 특징 변환(Feature Transformation)
특징을 변환하여 데이터의 분포를 변경하거나 차원을 축소하는 기법입니다.
(1) 로그 변환(Log Transformation)
- 분포가 오른쪽으로 치우쳐 있는 경우 로그 변환을 통해 정규 분포에 가깝게 만듦
df['feature'] = np.log1p(df['feature'])
(2) 차원 축소(Dimensionality Reduction)
- PCA(주성분 분석)을 이용해 특징 차원을 줄임
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
2. 회귀분석의 개념
2.1 주요 구성요소
- 종속 변수 (Dependent Variable, Y):
- 분석의 목표가 되는 변수입니다. 예를 들어, 판매량, 수익, 체중 등 예측하거나 설명하고자 하는 대상입니다.
- 독립 변수 (Independent Variable, X):
- 종속 변수에 영향을 주는 변수입니다. 예를 들어, 광고비, 교육 수준, 운동량 등이 해당됩니다.
- 오차항 (Error Term, ε):
- 모델이 설명하지 못하는 부분, 즉 관측된 값과 예측된 값 사이의 차이를 의미합니다. 이는 측정오차나 누락된 변수 등 여러 요인에 의해 발생할 수 있습니다.
2.2 회귀모델의 형태
회귀분석에서는 주어진 데이터에 가장 적합한 함수를 찾습니다. 이 함수는 선형(linear) 또는 비선형(nonlinear) 형태를 가질 수 있으며, 대표적인 방법으로 최소제곱법(OLS, Ordinary Least Squares)을 사용하여 모델의 파라미터를 추정합니다.
3. 단순 회귀 분석
단순 회귀 분석은 하나의 독립 변수와 하나의 종속 변수 사이의 선형 관계를 모델링하는 가장 기본적인 형태의 회귀분석입니다.

3.2 최소제곱법 (OLS)
단순 회귀 분석에서는 최소제곱법을 통해 $\beta_0$와 $\beta_1$를 추정합니다. 이 방법은 각 관측치에서 예측값과 실제값 사이의 잔차(residual)의 제곱합을 최소화하는 파라미터를 찾는 방법입니다.
- 잔차 분석: 잔차를 분석하면 모델이 데이터의 변동성을 얼마나 잘 설명하는지, 그리고 이상치나 패턴이 존재하는지 확인할 수 있습니다.
4. 회귀분석의 기본 가정
회귀모델이 올바르게 작동하려면 몇 가지 기본 가정이 충족되어야 합니다.
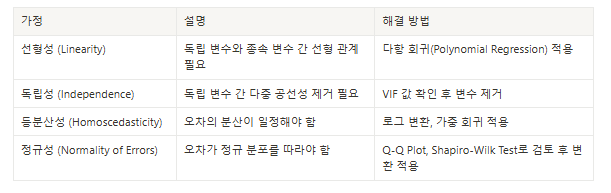
4.1 선형성 (Linearity)
독립 변수와 종속 변수 간의 관계가 선형이라는 가정입니다.
- 데이터가 선형적이지 않을 경우 비선형 변환이나 다른 모델링 기법이 필요할 수 있습니다.
4.2 독립성 (Independence)
각 관측치가 서로 독립적이어야 합니다.
- 시간 순서가 있는 데이터(예: 시계열 데이터)의 경우 자기상관 문제가 발생할 수 있으며, 이를 확인하고 보정할 필요가 있습니다.
4.3 등분산성 (Homoscedasticity)
모든 수준의 독립 변수에서 오차의 분산이 동일하다는 가정입니다.
- 만약 오차의 분산이 일정하지 않다면(이분산성), 모델의 추정치가 왜곡될 수 있습니다.
4.4 정규성 (Normality)
오차항이 정규분포를 따른다는 가정입니다.
- 이는 주로 추정치의 신뢰구간 및 가설 검정에서 중요한 역할을 하며, 정규성 검정을 통해 확인할 수 있습니다.
5. 모델 적합도 평가 및 검정
단순 회귀 분석을 통해 얻은 모델의 유의성과 적합도를 평가하는 여러 방법이 있습니다.
5.1 결정계수 (R²) - 주로 많이 쓰임
- R² 값: 종속 변수의 변동 중에서 모델이 설명하는 비율을 나타냅니다. 0과 1 사이의 값을 가지며, 1에 가까울수록 모델의 설명력이 좋음을 의미합니다.
- 결정계수( $R^2$ )는 회귀 모델이 데이터를 얼마나 잘 설명하는지를 나타내는 지표로, 다음과 같이 정의됩니다:


5.2 t-검정 및 p-값
- t-검정: 각 회귀계수가 통계적으로 유의한지를 검정합니다.
- p-값: 기울기나 절편이 0이라는 귀무가설을 기각할 수 있는지 판단합니다. 일반적으로 p-값이 0.05 미만이면 유의하다고 봅니다.
5.3 F-검정
- 전체 모델의 유의성을 검정하는 방법으로, 독립 변수가 종속 변수의 변동을 설명하는 데 유의한지를 평가합니다.
다중 선형 회귀와 모델 평가
1. 다중 선형 회귀 (Multiple Linear Regression)
- 다중 선형 회귀는 하나의 종속 변수(타겟 변수)를 여러 개의 독립 변수(설명 변수)를 사용하여 예측하는 회귀 분석 기법이다.
- 선형 회귀는 아래와 같은 수식으로 표현된다.
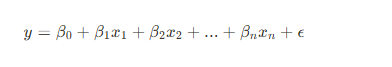

2. 모델 평가 지표
다중 선형 회귀 모델의 성능을 평가하기 위해 다음과 같은 주요 평가 지표를 사용한다.

3. 다중 선형 회귀 모델의 가정
모델을 올바르게 해석하고 활용하기 위해 아래 4가지 가정을 확인해야 한다.
- 선형성 (Linearity)
- 설명:
- 독립 변수(X)와 종속 변수(Y) 간의 관계가 선형이어야 한다.
- 즉, 독립 변수가 증가하거나 감소할 때 종속 변수도 일정한 비율로 증가하거나 감소해야 한다.
- 선형성이 깨지면 모델이 올바르게 예측하지 못할 수 있다.
- 실생활 예제:
- 예제 1: 공부 시간과 시험 점수
- 일반적으로 공부 시간이 많을수록 시험 점수가 높아진다.
- 하지만 일정 시간 이상 공부하면 피로도가 증가하면서 점수가 더 이상 선형적으로 증가하지 않을 수 있다.
- 예를 들어, 하루에 3~6시간 공부할 때는 점수가 선형적으로 증가하지만, 10시간 이상 공부하면 피로 때문에 점수가 떨어질 수도 있다.
- 이 경우 선형성이 깨질 수 있다.
- 예제 2: 광고 비용과 매출
- 광고 비용을 증가시키면 매출이 증가하는 경향이 있지만, 일정 수준 이상 광고를 하면 더 이상 매출이 증가하지 않을 수 있다.
- 예를 들어, 기존 고객이 이미 광고를 봤거나, 제품의 수요가 한계에 도달하면 광고 효과가 감소하는 곡선형 관계가 될 수 있다.
- 예제 1: 공부 시간과 시험 점수
2. 독립성 (Independence)
- 설명:
- 독립 변수들끼리는 서로 상관관계가 없어야 한다.
- 독립 변수 간에 다중 공선성(Multicollinearity)이 있으면 회귀 모델의 신뢰성이 떨어진다.
- 다중 공선성이 존재하면 특정 변수의 중요도를 해석하기 어려워진다.
- 실생활 예제:
- 예제 1: 집값 예측
- 집값을 예측할 때 ‘집의 크기(평수)’와 ‘방 개수’를 독립 변수로 사용한다고 가정하자.
- 일반적으로 집이 클수록 방 개수도 많아지므로, 두 변수가 서로 높은 상관관계를 갖는다.
- 즉, 하나의 변수를 알고 있으면 다른 변수도 거의 예측할 수 있다.
- 이처럼 독립 변수끼리 강한 상관관계가 있으면 다중 공선성이 발생하여 모델 해석이 어려워진다.
- 예제 2: 자동차 연비 예측
- 자동차 연비(종속 변수)를 예측할 때 ‘차량 무게’와 ‘엔진 배기량’을 독립 변수로 사용한다고 가정하자.
- 일반적으로 엔진 배기량이 클수록 차량 무게도 증가하는 경향이 있다.
- 이처럼 두 변수가 서로 강한 상관관계를 가지면 다중 공선성이 문제를 일으킬 수 있다.
- 예제 1: 집값 예측
vif 값
1~2 : 거의 없음
2~5 : 약간 있음
5~10 : 높음
10~ : 매우 높음
3. 등분산성 (Homoscedasticity)
- 설명:
- 독립 변수의 값이 변화하더라도 오차(Residual)의 분산이 일정해야 한다.
- 만약 등분산성이 깨지면 모델의 예측 성능이 특정 구간에서만 좋고, 다른 구간에서는 나쁠 수 있다.
- 이를 해결하기 위해 로그 변환, 정규화 등의 기법을 사용할 수 있다.
- 실생활 예제:
- 예제 1: 월 소득과 지출 예측
- 일반적으로 월 소득이 높아질수록 지출도 증가한다.
- 하지만 저소득층에서는 소득이 조금만 증가해도 소비 패턴이 크게 변하지만, 고소득층에서는 소득 증가가 소비 변화에 큰 영향을 미치지 않을 수 있다.
- 이 경우 등분산성이 깨져서 저소득층에서는 예측 오차가 크고, 고소득층에서는 예측이 더 정확할 수 있다.
- 예제 2: 학생들의 성적과 시험 스트레스
- 시험 성적이 낮은 학생들은 스트레스 수준이 매우 다양할 수 있다.
- 하지만 성적이 높은 학생들은 대체로 비슷한 스트레스 수준을 가질 가능성이 높다.
- 즉, 낮은 성적에서는 오차(스트레스 수준 차이)가 크고, 높은 성적에서는 오차가 작아질 수 있다.
- 이는 등분산성이 깨지는 경우에 해당한다.
- 예제 1: 월 소득과 지출 예측
4. 정규성 (Normality of Errors)
- 설명:
- 회귀 모델의 오차(Residuals)는 정규 분포를 따라야 한다.
- 오차가 정규성을 가지면 회귀 계수의 신뢰 구간을 정확하게 계산할 수 있고, 모델의 예측이 안정적이다.
- 정규성이 깨지면 t-검정이나 F-검정과 같은 통계적 검정이 잘못된 결론을 내릴 가능성이 높아진다.
- 실생활 예제:
- 예제 1: 제품 가격과 고객 구매율
- 일반적으로 제품 가격이 낮을수록 고객 구매율이 높아지지만, 가격이 너무 낮으면 품질이 의심되어 구매율이 감소할 수도 있다.
- 이러한 경우 오차가 정규 분포를 따르지 않을 가능성이 있다.
- 예제 2: 병원 환자의 대기 시간 예측
- 병원에서 환자의 대기 시간을 예측할 때, 대부분의 환자는 평균적인 대기 시간을 가지지만 특정 시간대(예: 점심시간, 야간 응급 상황)에는 대기 시간이 급격히 증가할 수 있다.
- 즉, 오차가 정규 분포를 따르지 않고 특정 구간에서 급격한 변화가 나타날 수 있다.
- 예제 1: 제품 가격과 고객 구매율
- 다중 선형 회귀 모델이 올바르게 작동하려면 위의 네 가지 가정을 충족해야 한다.
- 현실에서는 데이터가 항상 이상적인 가정을 만족하지 않으므로, 데이터 전처리, 변수 변환, 다중 공선성 제거, 정규화 기법 등을 활용하여 모델 성능을 향상시킬 필요가 있다.
위 가정을 만족하지 않을 경우, 다중 선형 회귀 모델이 적절하지 않을 수 있으며, 변환 기법이나 다른 모델을 고려해야 한다.
1. 로지스틱 회귀 개념
- 선형 회귀와 달리 종속 변수( $y$ )가 연속형이 아닌 이진 값(0 또는 1)을 가지는 경우 사용한다.
- 선형 회귀와 달리, 예측값을 0~1 사이의 확률 값으로 변환하기 위해 시그모이드 함수(Sigmoid Function) 를 적용한다.
시그모이드 함수(Sigmoid Function)
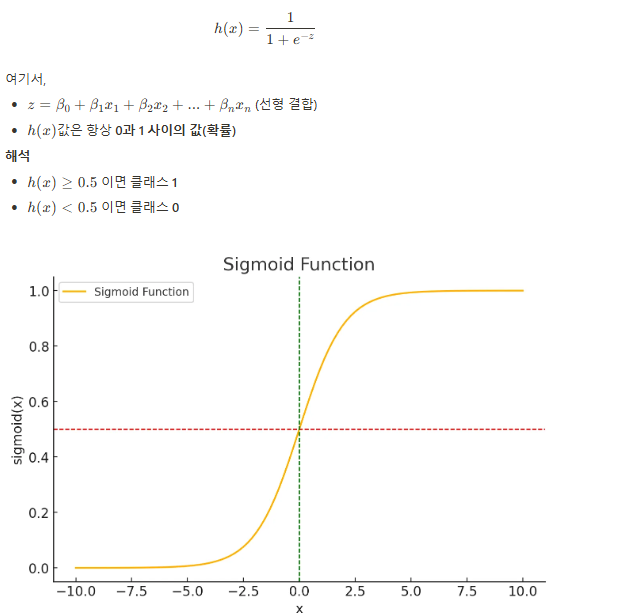
2. 활용 사례
로지스틱 회귀는 다양한 이진 분류 문제에서 활용된다.

그리고 오늘 개념중 헷갈렸던 모델 성능평가

(5) ROC-AUC (Receiver Operating Characteristic - Area Under Curve)
- ROC 곡선은 모델의 분류 성능을 시각적으로 평가하는 방법이다.
- AUC 값이 1에 가까울수록 모델이 긍정 클래스와 부정 클래스를 잘 구분한다는 의미.
- 임계값(Threshold)에 따라 Precision-Recall이 변화하는 경향을 분석 가능.
모델 성능 평가 - 티처블 머신을 통해 알아본다.(딥러닝)
티처블 머신 - 사과, 복숭아 모델 학습 후 TN TP FN FP 확인
사과, 복숭아 과일을 모델을 통해 분류한다.
사과 20개, 복숭아 20개 중 30% 비율(0.3)은 테스트 용으로 두고(사과 6, 복숭아 6 총 12개)
나머지를 티처블 머신을 사용하여 학습한 뒤 사과를 기준으로 TN TP FN FP로 분류를 한다.
50%확률을 넘기면 맞게 판단했다고 본다.
TP : (TRUE POSITIVE) - 모델에 사과를 넣었을 때 사과가 나온다면 정확한 예측
TN : (TRUE NEGATIVE ) - 모델에 복숭아를 넣었을 때 복숭아가 나온다면 정확한 예측
FP : (FALSE POSITIVE) - 모델에 복숭아를 넣었을 때 사과가 나온다면 오류
FN : (FALSE NEGATIVE) - 모델에 사과를 넣었을 때 복숭아가 나온다면 오류
모델이 사과를 기준으로 분리하기 때문에 분류 결과에 사과가 나온다면 POSITIVE
모델이 사과를 기준으로 분리하기 때문에 분류 결과에 복숭아가 나온다면 NEGATIVE
모델이 실제로사과를 넣었을 때 사과가 나오고 복숭아를 넣었을 때 복숭아가 나오면 TRUE
모델이 틀린 분류를 한다면 FALSE
이걸 조합해서 TP TN FP FN으로 분류하고

해당 식에 대입해서 계산하면 정확도가 나온다.
수업시간에 처음에는 어느정도 이해했던거 같은데 뭔가를 하나로 넣어야 한다는 말이 들리면서부터 혼동되기 시작했었다.
모델을 하나로 학습해서 사과 복숭아를 따로 테스트 하라는 말씀이신가? 분류 모델의 순서대로 P N이 정해지나? 하면서 혼란이 증폭됐다.
아무튼 이정도로 내용을 해석하고 배운 내용을 생각해보니 어느정도 들어맞는거 같다.
중요한건 분류 모델을 만들고 분석가의 기준에 P N을 정하는것. T F는 분류 결과로 나오니 모델이 정하는거 같다.


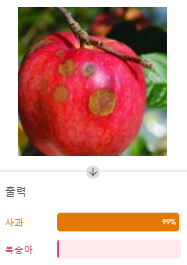


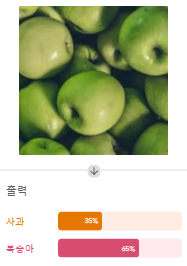
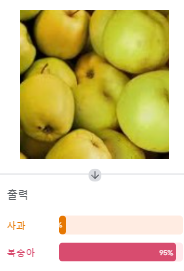
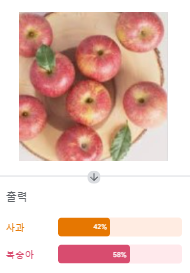
학습한 모델이 분류한 사과 이미지.
사과, 복숭아 확률 비슷하게 생기기도 했고 적은 개수를 학습해서 잘 분류하지는 못했다. 사과 6개중 3개를 복숭아로 분류했다.(FN 3)
그래도 3개는 사과라고 잘 분류했다.( TP 3)
나머지 복숭아는 복숭아로 분류했다고 가정하면 (TN 6)
TP (3)+ TN(6) / TP (3)+ TN(6) + FN(3) > 9/12 > 75% 정확도를 갖는다.
이제 어느정도 익숙해졌다고 생각했는데
역시 아직 넘어야 할 벽은 많았다.
목표는 시나리오, 데이터셋만 가지고 보고서 만들기
'그로스 마케팅' 카테고리의 다른 글
| 그로스 마케팅 26일차(분류 모델, 로지스틱 회귀 개념과 활용, k-nn, 서포트 벡터 머신(svm)) (0) | 2025.03.12 |
|---|---|
| 그로스 마케팅 25일차(머신러닝 :고객 재구매 예측 보고서 작성, 모델 성능평가, 결정트리, 랜덤포레스트 개념과 구현) (0) | 2025.03.11 |
| 멋사 그마 23일차(머신러닝 오버뷰, 로지스틱회귀를 통한 고객 세그먼트 웹서비스) (3) | 2025.03.07 |
| 그로스 마케팅 22일차(chart.js, 루커스튜디오 : 기초, db연동) (6) | 2025.03.06 |
| 그로스 마케팅 21일차(태블루, chart.js) (1) | 2025.03.05 |