머신러닝 3일차
이걸하기 위해 그동안 배웠다 라는 생각할 정도로 좋다는 느낌이 든다. 잘 배워보자~
몸상태가 안좋은건지 강사님 말씀도 좀 먹먹하게 들리는 기분이었다.
이제 데이터 수업은 얼마 안남았는데 끝까지 화이팅
학습목표
- 머신러닝 : 로지스틱 회귀분석을 통한 고객 재구매 예측 보고서 작성, 모델 성능 평가
- 결정트리, 랜덤포레스트 개념과 구현
고객 재구매 예측 (Customer Repurchase Prediction)
- 고객이 첫 구매 이후 재구매를 할 가능성을 분석하여 재구매 유도 마케팅 전략을 최적화한다.
- 로지스틱 회귀 모델을 활용하여 어떤 고객이 다시 구매할 가능성이 높은지 예측하고, 고객 충성도를 높이기 위한 프로모션 전략을 도출한다.
!pip install koreanize-matplotlib
import koreanize_matplotlib
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 데이터 로드
df = pd.read_csv("/content/customer_repurchase.csv")
# 데이터 분포 확인
plt.figure(figsize=(10, 6))
sns.histplot(df["First Purchase Amount ($)"], bins=30, kde=True, color='blue')
plt.title("첫 구매 금액 분포")
plt.xlabel("First Purchase Amount ($)")
plt.ylabel("Frequency")
plt.show()
# 첫구매후 경과일와 재구매 여부관계 시각화
plt.figure(figsize=(10, 6))
sns.boxplot(x="Repurchased", y="Days Since First Purchase", data=df)
plt.title("첫 구매이후 재구매 여부")
plt.xlabel("Repurchased (0=No, 1=Yes)")
plt.ylabel("Days Since First Purchase")
plt.show()
# 할인 제공 여부와 전환율 비교
plt.figure(figsize=(8, 5))
sns.barplot(x="Used Discount", y="Repurchased", data=df)
plt.title("할인 쿠폰 사용 여부와 재구매")
plt.xlabel("Used Discount (0=No, 1=Yes)")
plt.ylabel("Repurchased")
plt.show()
# 데이터셋 분리
X = df.drop(columns=["Repurchased"])
y = df["Repurchased"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 로지스틱 회귀 모델 학습
model = LogisticRegression()
model.fit(X_train, y_train)
# 예측 및 평가
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"모델 정확도: {accuracy:.2f}")
print("분류 보고서:\n", classification_report(y_test, y_pred))
# 혼동 행렬 시각화
plt.figure(figsize=(6, 4))
sns.heatmap(confusion_matrix(y_test, y_pred), annot=True, fmt='d', cmap='Blues')
plt.title("혼동 행렬")
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.show()




모델 성능 평가 및 다중 분류 개념
머신러닝 모델의 성능을 평가하는 것은 모델의 정확성, 일반화 성능, 실무 적용 가능성을 판단하는 중요한 과정이다. 특히 로지스틱 회귀 같은 이진 분류(Binary Classification) 모델과 다중 분류(Multi-Class Classification) 모델을 평가하는 방법이 다를 수 있다.
1. 모델 성능 평가 방법


2. 다중 분류(Multi-Class Classification)

근데 소프트 맥스 외에는 잘 안쓰인다고 하셨다.
소프트 맥스개념 설명하면서 나온 arg맥스 개념
소프트맥스 (Softmax)
소프트맥스는 다중 클래스 분류 문제에서 각 클래스에 속할 확률을 계산하는 함수입니다. 입력받은 값들을 0과 1 사이의 값으로 정규화하여 모든 클래스의 확률의 합이 1이 되도록 만듭니다.
argmax
argmax는 주어진 배열에서 가장 큰 값의 인덱스를 반환하는 함수입니다. 소프트맥스 함수의 결과로 얻은 확률 분포에서 가장 높은 확률을 가진 클래스를 선택하는 데 사용됩니다.
아래 예시에서 개는 0.5로 가장 큰 값이라 argmax로 선택 된다.
3. 다중 분류 모델 평가 방법
이진 분류와 마찬가지로 다중 분류에서도 정확도, Precision, Recall, F1-score 등을 활용하여 모델 성능을 평가할 수 있다.
다만 다중 분류에서는 각 클래스별로 Precision, Recall, F1-score를 구한 후 평균을 내는 방법을 사용한다.

결정 트리(Decision Tree) 기본 개념
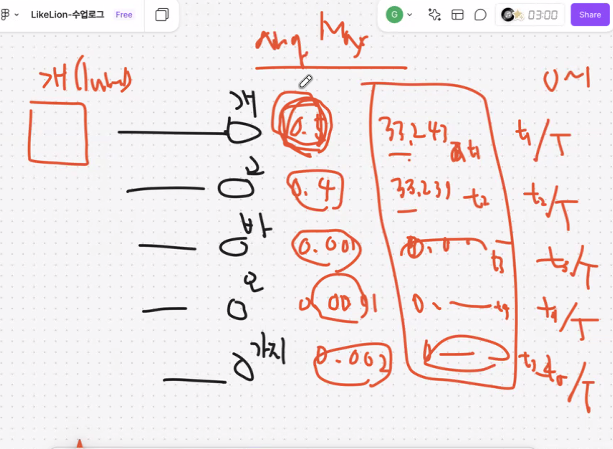
결정 트리(Decision Tree)는 트리(Tree) 구조를 사용하여 데이터를 분류(Classification)하거나 회귀(Regression)하는 지도 학습(Supervised Learning) 알고리즘이다. 트리의 각 노드는 특정 특징(feature)을 기준으로 데이터를 나누는 역할을 하며, 최종적으로 예측값(클래스 또는 수치)을 도출한다.

1. 결정 트리의 구조
결정 트리는 아래와 같은 트리 구조(Tree Structure) 로 이루어진다.
| 요소 | 설명 | 역할 |
| 루트 노드 (Root Node) | 데이터가 처음 입력되는 노드 |
가장 중요한 특징(Feature)을 기준으로 데이터를 나눔
|
| 내부 노드 (Internal Nodes) | 특정 특징을 기준으로 데이터를 분할(Split)하는 노드 |
질문(조건문)을 포함하여 데이터를 예/아니오 또는 특정 범위로 나눔
|
| 가지 (Branches) | 하나의 노드에서 데이터를 나누는 경로 |
조건을 만족하는 데이터가 새로운 노드(자식 노드)로 이동하는 경로 - 예, 아니오로 이동
|
| 단말 노드 (Leaf Nodes) | 더 이상 데이터를 나누지 않는 최종 노드 |
분류 문제에서는 클래스(0, 1, ...), 회귀 문제에서는 수치 예측 값을 나타냄
|
2. 결정 트리 학습 과정
결정 트리는 데이터를 기반으로 최적의 특징(feature)과 분할 조건(Split Condition)을 찾아 트리를 성장시키는 방식으로 학습한다.
(1) 분할 기준(Splitting Criteria)
- 결정 트리는 데이터를 분할할 때 어떤 특징(feature)이 가장 효과적으로 데이터를 나눌 수 있는지를 평가해야 한다.
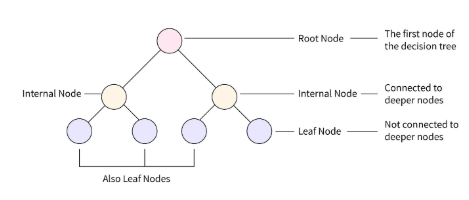
- 이를 위해 엔트로피(Entropy)와 지니 지수(Gini Index) 같은 수식을 사용하여 정보 이득(Information Gain) 을 계산한다.
엔트로피(Entropy)와 지니 계수(Gini Index) 실생활 사례
1. 엔트로피(Entropy)
예제: 편의점에서 손님이 어떤 음료를 선택할까?
- 편의점에서 손님이 콜라(50%), 사이다(50%) 를 고를 확률이 같다면, 어떤 음료를 선택할지 예측이 어렵다.
- 이 경우 엔트로피(불확실성)가 높음 → 엔트로피 값 ≈ 1
- 반면, 손님이 콜라(90%), 사이다(10%) 를 선택한다면?
- 콜라를 선택할 가능성이 매우 높아 예측이 쉬움 → 엔트로피 값 ≈ 0.47 (낮음)
결론:
- 엔트로피가 높을수록 선택이 랜덤(불확실)하므로, 데이터를 더 정밀하게 분류해야 함.
- 결정 트리는 엔트로피가 가장 크게 줄어드는(정보 이득이 높은) 기준으로 데이터를 나눔.
2. 지니 계수(Gini Index)
예제: 농구팀에서 선수 선발하기
- 농구팀을 꾸릴 때, 신장(키)에 따라 선수 선발을 한다고 가정하자.
- 만약 선수 10명 중 5명이 190cm 이상, 5명이 180cm 이하라면?
- 불순도가 높음 (팀 구성이 균등하여 선택이 어렵다) → 지니 계수 ≈ 0.5 (최대값)
- 하지만 선수 9명이 190cm 이상이고, 1명만 180cm 이하라면?
- 대부분 키가 크므로 불순도가 낮다 → 지니 계수 ≈ 0.18 (낮음)
결론:
- 지니 계수가 낮을수록 특정 그룹으로 쉽게 분류할 수 있음.
- 결정 트리는 지니 계수가 가장 낮아지는 기준으로 데이터를 나눔.
3. 엔트로피 vs 지니 계수 차이
| 비교 항목 | 엔트로피(Entropy) |
지니 계수(Gini Index)
|
| 개념 | 불확실성을 측정 |
그룹 간 불순도를 측정
|
| 최대값 | 0.5 vs 0.5 (동일 확률일 때) |
0.5 vs 0.5 (동일 확률일 때)
|
| 최소값 | 0 (완전히 한쪽으로 치우침) |
0 (완전히 한쪽으로 치우침)
|
| 특징 | 더 정밀하게 분류 | 계산이 더 빠름 |
| 사용 예제 | 광고 클릭 여부 예측 |
고객 만족도 그룹 분류
|
4. 실무 적용
- 엔트로피: 고객이 구매할 상품을 예측할 때 → 정보 이득(Information Gain)이 높은 기준으로 데이터를 나눔
- 지니 계수: 병원에서 질병 유무를 판단할 때 → 빠르고 간결한 계산으로 그룹을 나눔
💡 둘 다 불순도를 낮추는 역할을 하지만, 지니 계수는 계산이 더 빠르고, 엔트로피는 좀 더 정밀한 분류를 유도. 따라서 실제 프로젝트에서는 두 방법을 비교하여 더 좋은 결과를 내는 방식을 선택하는 것이 중요함.
엔트로피(Entropy)

지니 지수(Gini Index)

(2) 가지치기(Pruning)
- 결정 트리가 과적합(Overfitting) 되는 것을 방지하기 위해 불필요한 가지(branch)를 제거하는 과정
- 너무 많은 노드를 사용하면 데이터에 너무 맞춰진 복잡한 모델(Overfitting) 이 될 수 있음
사전 가지치기(Pre-Pruning)
- 트리가 성장하는 동안 미리 제한 조건을 설정하여 과적합을 방지
- 예제:
- 트리의 최대 깊이(Max Depth) 제한
- 최소 샘플 수(Min Samples Split) 제한
사후 가지치기(Post-Pruning)
- 먼저 트리를 최대한 성장시킨 후, 성능이 저하되지 않는 범위에서 가지를 제거하는 방법
- 불필요한 노드를 제거하여 모델을 단순화
3. 결정 트리의 장점과 단점
장점
- 해석이 쉬움(Interpretability)
- 트리 구조는 직관적이며 사람이 이해하기 쉬움
- "이 특징이 특정 값보다 크면 A, 작으면 B" 같은 논리적 규칙 기반으로 분류 가능
- 전처리가 거의 필요 없음
- 스케일링(Scaling) 필요 없음 (예: Min-Max Scaling, Standardization 불필요)
- 결측치(Missing Values)와 이상치(Outlier)에 강함
- 범주형 및 연속형 데이터 모두 처리 가능
- 숫자형 변수와 범주형 변수를 모두 다룰 수 있음
단점
- 과적합(Overfitting) 위험
- 트리가 너무 깊어지면 데이터에 너무 맞춰져 새로운 데이터 예측 성능이 낮아질 수 있음
- 해결 방법: 가지치기(Pruning) 또는 최소 샘플 수 제한 적용
- 작은 변화에도 민감(High Variance)
- 데이터가 조금만 바뀌어도 트리의 구조가 크게 달라질 수 있음
- 해결 방법: 랜덤 포레스트(Random Forest)와 같은 앙상블 기법 적용
- 비효율적인 분할 가능성
- 일부 데이터에서는 균형이 맞지 않는 트리(Unbalanced Tree) 가 생성될 수 있음
지니 계수(Gini Index)와 엔트로피(Entropy)에 의해 결정되는 임계값 예제
(1) 데이터 생성
아래 데이터는 특징 값(Feature)과 클래스(Label)로 이루어진 간단한 데이터셋이다.
특징 값이 5 이하일 때 클래스 0, 6 이상일 때 클래스 1로 분류된다.
| Feature | Class |
| 1 | 0 |
| 2 | 0 |
| 3 | 0 |
| 4 | 0 |
| 5 | 0 |
| 6 | 1 |
| 7 | 1 |
| 8 | 1 |
| 9 | 1 |
| 10 | 1 |
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
# 간단한 데이터 생성
X = np.array([[1], [2], [3], [4], [5], [6], [7], [8], [9], [10]]) # 특징값
y = np.array([0, 0, 0, 0, 0, 1, 1, 1, 1, 1]) # 클래스 값 (0 또는 1)
# 지니 계수를 사용한 결정 트리 모델
tree_gini = DecisionTreeClassifier(criterion="gini", max_depth=1, random_state=42)
tree_gini.fit(X, y)
# 엔트로피를 사용한 결정 트리 모델
tree_entropy = DecisionTreeClassifier(criterion="entropy", max_depth=1, random_state=42)
tree_entropy.fit(X, y)
# 임계값 출력
print("지니 계수를 사용한 분할 기준:", tree_gini.tree_.threshold[0])
print("엔트로피를 사용한 분할 기준:", tree_entropy.tree_.threshold[0])
(3) 코드 설명
- X: 1부터 10까지의 숫자로 이루어진 특징 값.
- y: 5 이하일 때 클래스 0, 6 이상일 때 클래스 1로 분류됨.
- DecisionTreeClassifier(criterion="gini"): 지니 계수를 사용한 트리 학습.
- DecisionTreeClassifier(criterion="entropy"): 엔트로피를 사용한 트리 학습.
- tree.tree_.threshold[0]: 트리에서 최초로 데이터를 나눈 임계값(Split Point)을 출력.
(4) 결과 예측
- 지니 계수와 엔트로피는 데이터에서 가장 최적의 분할 기준(임계값)을 자동으로 계산한다.
- 예상되는 결과:
- 두 방식 모두 5.5를 기준으로 데이터를 나눔.
- 하지만 특정 데이터셋에서는 다른 임계값이 선택될 수도 있음.
- 지니 계수를 사용한 분할 기준: 5.5 엔트로피를 사용한 분할 기준: 5.5
예제 5: 주어진 데이터셋을 이용해 특정 지역의 매출건수예시.
“서울시 상권분석 데이터.csv” 데이터셋을 이용해 “사가정역”에서의 “당월매출건수”를 예측하는 회귀 코드 예시 입니다. ^^
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor, plot_tree
from sklearn.metrics import mean_absolute_error, r2_score
# 1. CSV 파일 로드
file_path = "서울시 상권분석 데이터.csv" # CSV 파일 경로 입력
df = pd.read_csv(file_path, encoding="utf-8")
# 2. "사가정역" 데이터 필터링
df = df[df["상권_코드_명"] == "사가정역"]
# 3. 필요없는 컬럼 제거
drop_columns = ["기준_년분기_코드", "상권_구분_코드", "상권_구분_코드_명", "상권_코드", "상권_코드_명",
"서비스_업종_코드", "서비스_업종_코드_명"] # 분석에 필요 없는 컬럼 제거
df = df.drop(columns=drop_columns)
# 4. 결측값 제거
df = df.dropna()
# 5. 입력(X)과 타겟(y) 분리
X = df.drop(columns=["당월_매출_건수"]) # 입력 변수 (매출 건수를 예측해야 하므로 제외)
y = df["당월_매출_건수"] # 타겟 변수 (예측 대상)
# 6. 데이터 분할 (훈련 80%, 테스트 20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 7. 결정트리 회귀 모델 학습
dt_model = DecisionTreeRegressor(max_depth=5, random_state=42)
dt_model.fit(X_train, y_train)
# 8. 모델 예측 및 평가
y_pred = dt_model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Absolute Error (MAE): {mae:.2f}")
print(f"R² Score: {r2:.2f}")
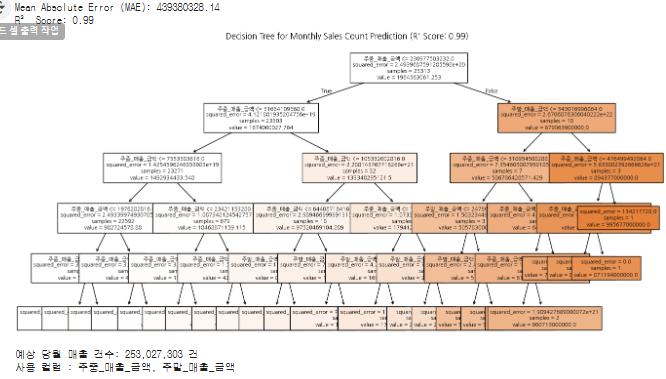
# 9. 결정 트리 시각화
fig, ax = plt.subplots(figsize=(15, 8))
plot_tree(dt_model, feature_names=X.columns, filled=True, ax=ax, fontsize=8)
plt.title(f"Decision Tree for Monthly Sales Count Prediction (R² Score: {r2:.2f})")
plt.show()
# 10. 예측 함수
def predict_sales_count(data_input):
input_data = pd.DataFrame([data_input], columns=X.columns)
prediction = dt_model.predict(input_data)
return f"예상 당월 매출 건수: {prediction[0]:,.0f} 건"
# 예측 예시
sample_input = X.iloc[0].values # 첫 번째 샘플 데이터로 예측
print(predict_sales_count(sample_input))
그리고 활용한 문제
문제 1. 다음의 데이터셋을 이용하여 발달상권의 당월 매출금액을 예측하는 예측모델을 개발하세요
- 결정트리 알고리즘을 사용해서 예측모델을 만드세요.
- 예측정확도를 90% 이상 충족하고
- 위 예측모델을 만들기 위한 독립변수를 제시하세요.(drop로 출력을 해서 상위 독립변수를 출력할 수도 있고 산업군에 대해 잘 안다면 직접 컬럼을 넣기도 한다고 잼미니가 그랬다.)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor, plot_tree
from sklearn.metrics import mean_absolute_error, r2_score
# 1. CSV 파일 로드
file_path = "/content/서울시 상권분석 데이터.csv" # CSV 파일 경로 입력
df = pd.read_csv(file_path, encoding="utf-8")
# 2. "사가정역" 데이터 필터링
df = df[df["상권_구분_코드_명"] == "발달상권"]
# 3. 필요없는 컬럼 제거
drop_columns = ["기준_년분기_코드", "상권_구분_코드", "상권_구분_코드_명", "상권_코드", "상권_코드_명",
"서비스_업종_코드", "서비스_업종_코드_명"] # 분석에 필요 없는 컬럼 제거
df = df.drop(columns=drop_columns)
# 4. 결측값 제거
df = df.dropna()
# 5. 입력(X)과 타겟(y) 분리
#X = df.drop(columns=["당월_매출_금액"]) # 입력 변수 (매출 건수를 예측해야 하므로 제외)
X = df[["주중_매출_금액", "주말_매출_금액"]]
y = df["당월_매출_금액"] # 타겟 변수 (예측 대상)
# 6. 데이터 분할 (훈련 80%, 테스트 20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 7. 결정트리 회귀 모델 학습
dt_model = DecisionTreeRegressor(max_depth=5, random_state=42)
dt_model.fit(X_train, y_train)
# 8. 모델 예측 및 평가
y_pred = dt_model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Absolute Error (MAE): {mae:.2f}")
print(f"R² Score: {r2:.2f}")
# 9. 결정 트리 시각화
fig, ax = plt.subplots(figsize=(15, 8))
plot_tree(dt_model, feature_names=X.columns, filled=True, ax=ax, fontsize=8)
plt.title(f"Decision Tree for Monthly Sales Count Prediction (R² Score: {r2:.2f})")
plt.show()
# 10. 예측 함수
def predict_sales_count(data_input):
input_data = pd.DataFrame([data_input], columns=X.columns)
prediction = dt_model.predict(input_data)
return f"예상 당월 매출 건수: {prediction[0]:,.0f} 건"
# 예측 예시
sample_input = X.iloc[0].values # 첫 번째 샘플 데이터로 예측
print(predict_sales_count(sample_input))
print("사용 컬럼 : 주중_매출_금액, 주말_매출_금액")
근데 뭔가가 문제인지 데이터 분할에서 오류가 생기는 경우가 꽤 있었다.
그리고 데이터 분할에서 0.2/0.3 이런것은 입력 순서대로 가장 마지막의 0.2/0.3 만큼의 비율을 테스트 데이터로 사용하겠다는 뜻. 랜덤 비율이 아님
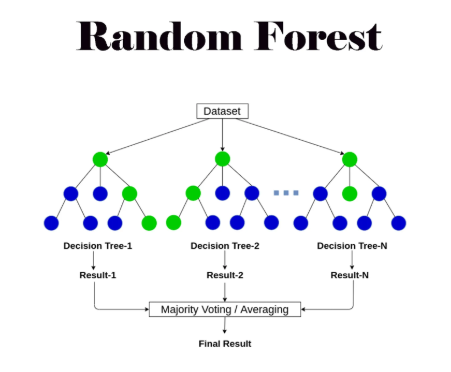
랜덤 포레스트(Random Forest) 개념과 구현
랜덤 포레스트(Random Forest)는 여러 개의 결정 트리(Decision Tree)를 조합하여 예측 성능을 향상시키는 앙상블 학습(Ensemble Learning) 기법이다. 단일 결정 트리의 한계를 극복하고 과적합(Overfitting)을 줄이며, 예측 성능을 개선하는 데 효과적이다.
1. 랜덤 포레스트 개념
랜덤 포레스트는 배깅(Bagging, Bootstrap Aggregating) 방식을 기반으로 여러 개의 결정 트리를 학습하고,
각 트리의 예측을 평균(회귀) 하거나 투표(분류) 하여 최종 예측을 수행한다.
(1) 랜덤 포레스트의 특징
- 여러 개의 결정 트리를 조합하여 예측
- 하나의 모델이 아닌 다수의 결정 트리를 훈련하여 결과를 조합함.
- 단일 결정 트리보다 일반화 성능(Generalization) 이 높아짐.
- 배깅(Bagging) 기법 사용
- 데이터 샘플링(부트스트랩 샘플링, Bootstrap Sampling)을 통해 중복된 데이터를 포함한 여러 개의 훈련 데이터셋을 생성.
- 각 트리는 서로 다른 데이터 샘플을 사용하여 학습됨.
- 랜덤한 특징 선택
- 각 트리는 전체 데이터가 아닌 일부 랜덤한 특징(Feature Subset) 을 사용하여 분할(Split) 수행.
- 이렇게 하면 특정 변수에 의존하는 문제를 방지하고, 모델의 다양성을 증가시킴.
- 결과 결합 방법
- 분류(Classification): 개별 트리의 예측 중 가장 많은 표를 받은 클래스(다수결, Majority Voting) 를 선택.
- 회귀(Regression): 개별 트리의 예측값을 평균 하여 최종 결과를 생성.
2. 랜덤 포레스트의 장점과 단점
(1) 장점
- 과적합(Overfitting) 방지
- 여러 개의 트리를 조합하여 사용하므로 단일 결정 트리보다 과적합 가능성이 낮음.
- 높은 예측 성능
- 다양한 트리의 결과를 조합하기 때문에 단일 결정 트리보다 일반화 성능이 뛰어남.
- 특징 중요도 제공
- 랜덤 포레스트는 각 특징(Feature)이 예측에 미치는 영향을 평가할 수 있어 특징 선택(Feature Selection)에 유용.
- 다양한 데이터 유형 지원
- 숫자형 변수 및 범주형 변수를 모두 처리 가능.
(2) 단점
- 훈련 속도가 느림
- 개별 결정 트리 여러 개를 학습해야 하므로 단일 결정 트리보다 훈련 시간이 오래 걸림.
- 해석이 어려움
- 단일 결정 트리는 해석이 쉽지만, 랜덤 포레스트는 여러 개의 트리를 조합하기 때문에 직관적으로 이해하기 어려움.
- 메모리 사용량이 많음
- 여러 개의 트리를 저장해야 하므로 메모리 사용량이 큼.
정말 느렸다. 좀 오래된 데스크탑이긴 하지만 서울시 데이터로 반복문을 사용해서 모든 항목을 출력해보려고 시도했을 때
느리다는 말이 뭔지 체감됐다.
그리고 랜덤 포레스트는 결정트리 처럼 각각의 트리로 시각화 할 수 도 있다고 하지만
바차트로 큰 특징을 비교한다.(산점도로도 나타낸 예제가 있음)
(3) 주어진 데이터셋을 이용해 특정 지역의 매출건수예시
“서울시 상권분석 데이터.csv” 데이터셋을 이용해 “사가정역”에서의 “당월매출건수”를 예측하는 Random forest 회귀 코드 예시 입니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error, r2_score
# 1. CSV 파일 로드
file_path = "서울시 상권분석 데이터.csv" # CSV 파일 경로 입력
df = pd.read_csv(file_path, encoding="utf-8")
# 2. "사가정역" 데이터 필터링
df = df[df["상권_코드_명"] == "사가정역"]
# 3. 필요없는 컬럼 제거
drop_columns = ["기준_년분기_코드", "상권_구분_코드", "상권_구분_코드_명", "상권_코드", "상권_코드_명",
"서비스_업종_코드", "서비스_업종_코드_명"] # 분석에 불필요한 컬럼 제거
df = df.drop(columns=drop_columns)
# 4. 결측값 제거
df = df.dropna()
# 5. 입력(X)과 타겟(y) 분리
X = df.drop(columns=["당월_매출_건수"]) # 입력 변수
y = df["당월_매출_건수"] # 타겟 변수 (예측 대상)
# 6. 데이터 분할 (훈련 80%, 테스트 20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 7. 랜덤포레스트 회귀 모델 학습
rf_model = RandomForestRegressor(n_estimators=100, max_depth=5, random_state=42)
rf_model.fit(X_train, y_train)
# 8. 모델 예측 및 평가
y_pred = rf_model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Absolute Error (MAE): {mae:.2f}")
print(f"R² Score: {r2:.2f}")
# 9. 변수 중요도 시각화
feature_importances = rf_model.feature_importances_
sorted_idx = np.argsort(feature_importances)[::-1]
plt.figure(figsize=(10, 6))
plt.bar(range(X.shape[1]), feature_importances[sorted_idx], align="center")
plt.xticks(range(X.shape[1]), X.columns[sorted_idx], rotation=90)
plt.xlabel("Feature")
plt.ylabel("Importance")
plt.title("Feature Importance in Random Forest Model")
plt.show()
# 10. 예측 함수
def predict_sales_count(data_input):
input_data = pd.DataFrame([data_input], columns=X.columns)
prediction = rf_model.predict(input_data)
return f"예상 당월 매출 건수: {prediction[0]:,.0f} 건"
# 예측 예시
sample_input = X.iloc[0].values # 첫 번째 샘플 데이터로 예측
print(predict_sales_count(sample_input))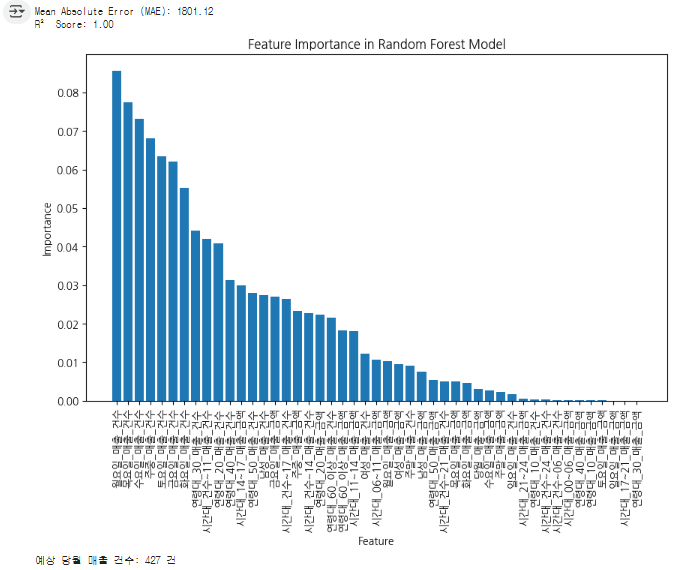
머신러닝이 잘 맞으니 정말 재밌는것 같다.
근데 개념이나 코드들이 생소한게 많아서 어디를 건드려야 할지 어렵기도 하고...
딥러닝은 더 재밌다고 하셨다.
'그로스 마케팅' 카테고리의 다른 글
| 그로스 마케팅 27일차(딥러닝 1일차 ANN: 단층,다층,심층신경망 - 주가 예측, CNN-티처블 머신으로 웹서비스, K평균 군집화-분류) (11) | 2025.03.13 |
|---|---|
| 그로스 마케팅 26일차(분류 모델, 로지스틱 회귀 개념과 활용, k-nn, 서포트 벡터 머신(svm)) (0) | 2025.03.12 |
| 그로스 마케팅 24일차(데이터 전처리, 특징엔지니어링, 선형회귀/다중 선형회귀, 로지스틱 회귀 , 모델 성능 평가 - 티처블 머신으로 정확도 개념 잡기) (3) | 2025.03.10 |
| 멋사 그마 23일차(머신러닝 오버뷰, 로지스틱회귀를 통한 고객 세그먼트 웹서비스) (3) | 2025.03.07 |
| 그로스 마케팅 22일차(chart.js, 루커스튜디오 : 기초, db연동) (6) | 2025.03.06 |